
Celery Cookbook
Table of content:
About
Celery 是个分布式消息队列。简单,灵活,且可靠。这是一篇会持续更新并且会很长的文章,致力解决的问题:
- Celery 的架构和原理
- 一些核心概念
- 和其他消息队列的对比
- 结合自己使用和看书了解到的最佳实践
- 在 Celery 使用过程中遇到过的一些问题,使用场景,以及背后的原理
不包括:
- Celery 的安装使用和常见功能介绍
还会继续扩展或还有疑问的部分会被标记成 todo 。
Celery 核心
包含的组件
Celery Beat 任务调度器 (todo)
Beat 进程会读取配置文件的内容,周期性地将配置中到期需要执行的任务发送给任务队列
Celery Worker, 执行任务的消费者
通常会在多台服务器运行多个消费者来提高执行效率
Broker 消息代理
或者叫作消息中间件,接受任务生产者发送过来的任务消息,存进队列再按序分发给任务消费者 worker。
Broker 的选择大致有消息队列和数据库两种(这里建议尽量避免使用数据库作为 Broker,后文最佳实践中有提及)。
Celery 官方是推荐使用 RabbitMQ 来做 broker,有很多成功的案例。工业上,很多项目是使用 RabbitMQ 作为 Broker,Redis 用来存储结果。
todo: 对比 RabbitMQ 和 Redis
Producer 生产者
调用了 Celery 提供的 API、函数或者装饰器而产生任务并交给任务队列处理的都是任务生产者
Result Backend, 任务处理完后保存状态信息和结果,以供查询
Celery 默认已支持 Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy 等方式
Workflow
和其他任务队列的比较(todo)
轻量级的替代方案:
RQ: Simple job queues for Python http://python-rq.org/
一个更加复杂完善,但是原理不同
Pyro - Python Remote Objects - 4.60 — Pyro 4.60 documentation https://pythonhosted.org/Pyro4/
最佳实践
尽量不要使用数据库作为 AMQP Broker
Broker 的选择大致有消息队列和数据库两种,这里建议尽量避免使用数据库作为 Broker,除非你的业务系统足够简单。
在并发量很高的复杂系统中,大量 Workers 访问数据库的行为会使得操作系统磁盘 I/O 一直处于高峰值状态,非常影响系统性能。如果数据库 Broker 同时还兼顾着后端业务的话,那么应用程序也很容易被拖垮。
反观选择消息队列,例如 RabbitMQ,就不存在以上的问题。首先 RabbitMQ 的队列存放到内存中,速度快且不占用磁盘 I/O。再一个就是 RabbitMQ 会主动将任务推送给 Worker,所以 Worker 无需频繁的去轮询队列,避免无谓的资源浪费。
todo: RabbitMQ 和其他 Broker 的对比结果
使用多个队列 (todo)
对于不同的 task ,尽量使用不同的队列来处理。以下是一个简化模型:
1 | @app.task() |
1 | task_queues=( |
1 | @app.task(queue='other') |
定义具有优先级的 workers
善用任务工作流
Celery 支持 group/chain/chord/chunks/map/starmap 等多种工作流原语,基本可以覆盖大部分复杂的任务组合需求,善用任务工作流能够更好的应用 Celery 优秀的并发特性。
- chain, 下一步任务需要等待上一步任务的执行结果,或者任务是按顺序串行的情况
- chord
例如,如果下一步任务需要等待上一步任务的执行结果,那么不应该单纯的应用 get 方法来实现同步子任务,而是应该使用 chain 任务链。
尽量不要以同步阻塞的方式调用子任务,而是用异步回调的方式进行链式任务的调用, 比如以下的例子:
- update_page_info, 正确方式,平均耗时 252.3190975189209
- update_page_info_01, 错误示范,平均耗时 3129.5740604400635
1 | def update_page_info(url): |
1 | @app.task() |
使用 celery 的错误处理机制
不要将 Database/ORM 对象传入 tasks
不应该讲 Database objects 比如一个 User Model 传入在后台执行的任务,因为这些 object 可能包含过期的数据。相反应该传入一个 user id ,让 task 在执行过程中向数据库请求全新的 User Object。
设置 task 超时
推荐设置一个全局的 Soft timeout 时间,再根据 Task 类型单独设置一些特别的,防止一些长时间运行的任务阻塞
1 | # Add a one-minute timeout to all Celery tasks. |
1 | @app.task(soft_time_limit=5) |
将大型 task 作为类
做一些统一的日志和错误日志等, 非常方便
1 | # -*- coding: utf-8 -*- |
任务状态回调
| 参数 | 说明 |
|---|---|
| PENDING | 任务等待中 |
| STARTED | 任务已开始 |
| SUCCESS | 任务执行成功 |
| FAILURE | 任务执行失败 |
| RETRY | 任务将被重试 |
| REVOKED | 任务取消 |
也就是可以通过新定义一个状态,在执行等待中获取。但是实测下来 on_message 在部分场景下是不支持的, 比如 Celery 版本和 broker 类型。
1 | @app.task(bind=True) |
设置 worker 的数量
Celery 默认会开启和 CPU core 一样数量的 worker,如果想要不想开启多个 worker ,可以通过启动时指定 –concurrency 选项
1 | --concurrency=1 |
单元测试
直接调用 worker task 中的方法,不要使用 task.delay() 。 或者使用 Eager Mode,使用 task_always_eager 设置来启用,当启用该选项之后,task 会立即被调用。而这两种方式都只能测试 task worker 中的内容,官方并不建议这么做。
官方文档在 task_always_eager 里面的描述是:
If this is True, all tasks will be executed locally by blocking until the task returns. apply_async() and Task.delay() will return an EagerResult instance, that emulates the API and behavior of AsyncResult, except the result is already evaluated.
That is, tasks will be executed locally instead of being sent to the queue.
- Testing with Celery — Celery 4.2.0 documentation http://docs.celeryproject.org/en/latest/userguide/testing.html
- task_always_eager http://docs.celeryproject.org/en/latest/userguide/configuration.html#std:setting-task_always_eager
对于执行时间长短不一的任务建议开启 -Ofair
用 文章 里面的图片能非常快速说明问题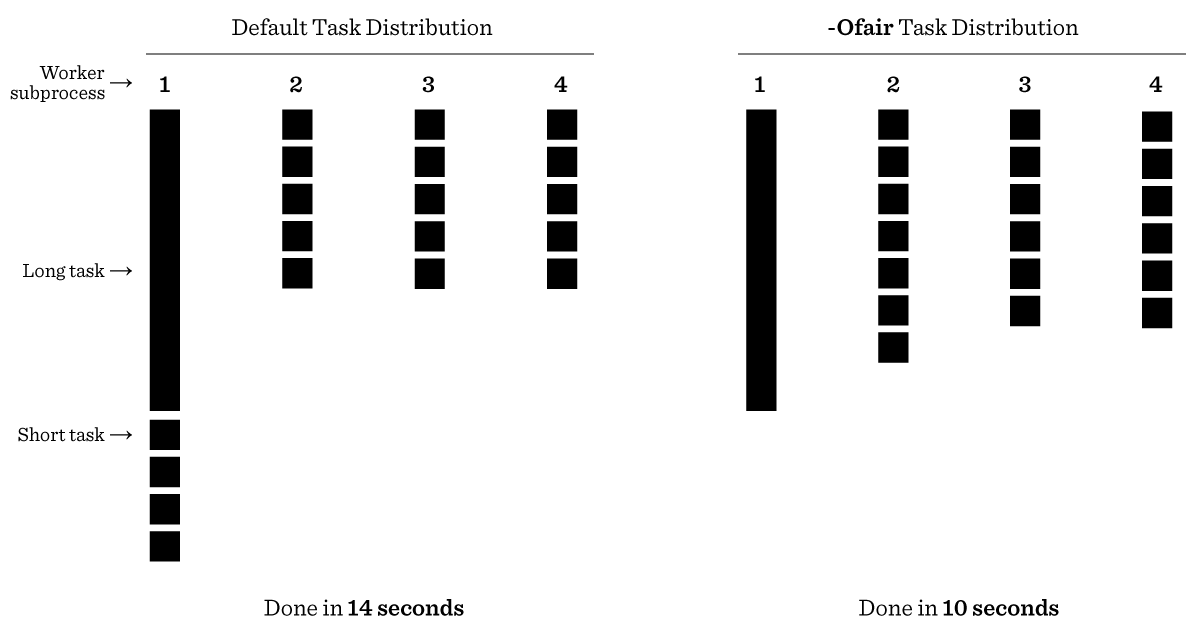
也就是说 Celery 默认会平均分配任务给 worker,不管当前 worker 是否繁忙。如果如果任务的时间差别非常大时,就比较明显了。在启动命令里面加上 -Ofair 可以关闭这样的特性。
这样做会带来一些调度上的开销,但是整个行为会好预测很多。
Ref:
- Optimizing — Celery 4.2.0 documentation https://celery.readthedocs.io/en/latest/userguide/optimizing.html#prefork-pool-prefetch-settings
启动任务监控
Flower 是 Celery 官方推荐的实时监控工具,用于监控 Tasks 和 Workers 的运行状态。Flower 提供了下列功能:
- 查看 Task 清单、历史记录、参数、开始时间、执行状态等
- 撤销、终止任务
- 查看 Worker 清单、状态
- 远程开启、关闭、重启 Worker 进程
- 提供 HTTP API,方便集成到运维系统
- 相比查看日志,Flower 的 Web 界面会显得更加友好。
使用场景和常见问题
Reserve one task at a time 含义是什么 ?(todo)
在 文档
里面提到了一个优化思路
deply 和 apply_async 的区别
deply 是 apply_async 的一个快捷使用方式,
从 文档 看到 apply_async 支持更多复杂的控制, 比如:
- 重试次数,重试策略, 每次重试等待时间
- expires, 任务过期时间
- countdown, Number of seconds into the future that the task should execute, 默认为立刻执行
- 任务的队列,优先级
Ref:
- delay & apply_async http://docs.celeryproject.org/en/latest/getting-started/first-steps-with-celery.html#calling-the-task
- apply_async API: http://docs.celeryproject.org/en/latest/reference/celery.app.task.html#celery.app.task.Task.apply_async
worker 启动日志里面的 concurrency: x (prefork) 含义(todo)
worker 设置超时时间, Soft time limit 和 Time Limit 区别
1 | @app.task(bind=True, soft_time_limit=1, time_limit=3) |
超过设置的 soft limit 之后,会抛一个 SoftTimeLimitExceeded(), task 里面可以对这样的错误进行处理:
1 | [2018-12-17 00:12:43,267: WARNING/MainProcess] Soft time limit (1s) exceeded for task_name[task_id] |
但是如果是 hard time limit, worker 会被 kill 掉,任务也就会被强制结束,日志如下:
1 | [2018-12-17 00:12:45,275: ERROR/MainProcess] Task task_name[task_id] raised unexpected: TimeLimitExceeded(3,) |
Ref:
- http://docs.celeryproject.org/en/latest/userguide/configuration.html#task-soft-time-limit
- http://docs.celeryproject.org/en/latest/userguide/configuration.html#task-time-limit
Reference & Recommendation
- Three quick tips from two years with Celery – Taylor Hughes – Medium https://medium.com/@taylorhughes/three-quick-tips-from-two-years-with-celery-c05ff9d7f9eb
- 《Python分布式计算》 第4章 Celery分布式应用 (Distributed Comp… - 简书 https://www.jianshu.com/p/ee14ed9e4989
- Deni Bertovic :: Celery - Best Practices https://denibertovic.com/posts/celery-best-practices/
- Celery 最佳实践 | Verne in GitHub http://einverne.github.io/post/2017/05/celery-best-practice.html
- 分布式队列神器 Celery | RaPoSpectre的个人博客 https://www.rapospectre.com/blog/celery-user-guide
更新日志
- 2018-12-18 根据自己的使用和理解,列了一些 Celery 的最佳实践和一些常见问题
关于头图
拍摄自费城